-
👩💻 성능 최적화 방식
💚 데이터를 이용한 성능 최적화
- 최대한 많은 데이터 수집하기

딥러닝과 머신러닝의 성능 비교 - 데이터 생성
(이미지 조작 코드 - 앞 5장 참고하여 작성하기)
- 데이터 범위 조정하기(스케일링)
활성화 함수인 시그모이드를 사용한다면 데이터셋 범위를 0~1의 값을 갖도록 하고, 하이퍼볼릭 탄젠트를 사용한다면 데이터셋 범위를 -1~1의 값을 갖도록 조정하는 것이 가능하다.
알고리즘 튜닝을 위한 성능 최적화
알고리즘 성능 평가 방식
- accuracy, F1 score, AP 메트릭스 등의 정확도 검증을 통한 판별

성능 비교
훈련(train) 성능 >>> 검증(test) 성능
- 과적합 의심
- 해결책으로 규제화하기
훈련과 검증 결과가 모두 성능이 좋지 않은 상황
- 과소적합 의심
- 에포크 수 줄이기
가중치
- 가중치에 대한 초깃값은 작은 난수를 사용해보기
- 비지도 학습을 이용하여 사전 훈련(가중치 정보를 얻기 위한 사전 훈련)을 진행한 후 지도 학습을 진행해보기
학습률
- 학습률은 모델의 네트워크 구성에 따라 다르기 때문에 초기에 매우 크거나 작은 임의의 난수를 선택하여 학습 결과를 보고 조금씩 변경해보는 것
- 네트워크의 층이 많다면 학습률이 높아야 하며, 네트워크의 층이 적다면 학습률이 적어야 된다.
활성화 함수
- 일반적으로는 활성화 함수로 시그모이드나 하이퍼볼릭 탄젠트를 사용한다면 출력층에서는 소프트맥스나 시그모이드 함수를 많이 선택해서 사용한다.
배치와 에포크
- 큰 에포크와 작은 배치를 사용하기
- 훈련 데이터셋의 크기를 동일하게 하거나 하나의 배치로 실험삼아서 훈련 진행해보기
옵티마이저와 손실함수
- 일반적으로 확률적 경사하강법(로지스틱 회귀 방식)을 주로 사용함
- 손실함수로는 아담이나 RMSProp 사용함
네트워크 구성
- 하나의 은닉층에 뉴런을 여러 개 포함시키거나(네트워크가 넓다고 표현), 네트워크 계층을 늘리되 뉴런 개수는 줄여 보면서(네트워크가 깊다고 표현) 최적의 네트워크를 구축해보기
앙상블을 이용한 성능 최적화
앙상블이란?
간단히 모델을 두 개 이상 섞어서 사용해보기
하이퍼 파라미터를 이용한 성능 최적화
배치 정규화 , 규제화, 표준화
정규화란(normalization)?
- 데이터 범위를 사용자가 원하는 범위로 제한하는 것을 의미한다.
- 이미지 데이터는 픽셀 정보로 0~255 사이의 값을 갖게 되는데, 이를 255로 나누어 0.1~1 사이로 조정하는 것 등을 의미
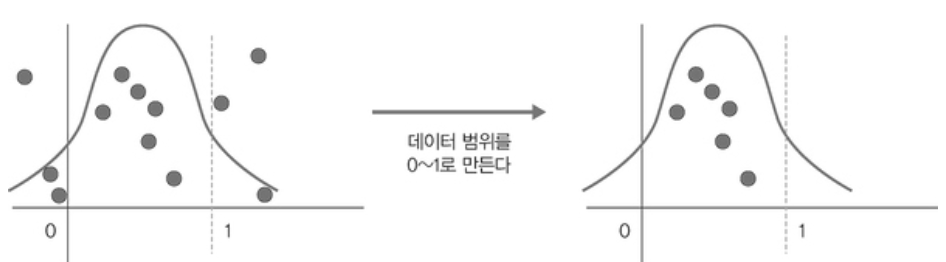
- feature scaling(피처 스케일링)으로도 표현하기도 함
- MinMaxScaler() 를 주로 사용
MinMaxScaler 수식

- 기울기 소멸, 기울기 폭발 문제를 해결하기 위함
- 물론 손실함수로 ReLU를 사용하는 방법이나 초깁갓 튜닝, lr 설정 등 역시 쓰이기도 하지만 이들과 다같이 쓰이는 것이 배치 정규화이다.

** 내부 공변량 변화
- 기울기 소멸과 폭발을 유발하는 원인
- 네트워크의 각 층마다 활성화 함수가 적용되면서 입력 값들의 분포가 계속 바뀌게 만드는 것
미니배치 정규화 과정


① 미니 배치 평균을 구하기
② 미니 배치의 분산과 표준편차를 구함
③ 정규화를 수행한다.
④ 스케일(scale)을 조정(데이터 분포 조정)한다.
규제화(regulation)
- 모델 복잡도를 줄이기 위해 제약을 두는 방법
- 데이터가 네트워크에 들어가기 전에 필터를 적용한 것
- 드롭아웃

드롭아웃
- 훈련할 때 일정 비율의 뉴런만 사용하고 나머지 뉴런에 해당하는 가중치는 업데이트하지 않는 것
- 은닉층에 배치한 노드를 임의로 끄면서 학습함
- 어떤 노드를 비활성화할지는 학습할 때마다 무작위로 선정되며, 테스트 데이터로 평가할 때는 노드들을 모두 사용하여 출력하되 노드 삭제 비율(드롭아웃 비율)을 곱해서 성능을 평가한다.

💚 FASHIONMNIST 데이터셋을 통하여 배치 정규화 구현하기
✍ 라이브러리 호출
import torch import matplotlib.pyplot as plt import numpy as np import torchvision import torchvision.transforms as transforms import torch.nn as nn import torch.optim as optim✍ FashionMNIST 데이터셋(이미지 데이터) 불러오기
trainset = torchvision.datasets.FashionMNIST( root='..data/', train=True, download=True, transform=transforms.ToTensor()) # root = '' : ''라는 디렉토리에 다운받은 데이터셋을 넣는다. #transform=transforms.ToTensor() : 다운받은 데이터셋을 텐서형식으로 변환한다. #데이터셋은 trainset이라는 변수 안에 저장된다.✍ 데이터셋을 메모리로 가져오기
batch_size = 4 # 데이터를 메모리로 가져올 때 한 번에 네 개씩(미니배치 크기) 쪼개서 가져옴 trainloader = torch.utils.data.DataLoader(trainset, batch_size =batch_size, shuffle=True ) # trainloader이라는 변수는 DataLoader로 데이터셋을 메모리로 가져오는 행위 자체를 넣은 것✍ 데이터셋 분리하기
dataiter = iter(trainloader) #trainloader에서 원소를 하나씩 꺼내오는 것을 dataiter에 저장시킴 images, labels = dataiter.next() #dataiter.next()로 하나씩 꺼내온 것을 각각 images, labels로 나눠서 저장한다. print(images.shape) print(images[0].shape) print(labels[0].item())images.shape
[batch_size, channels, height, width] 로 출력
- batch_size : 배치에 포함된 이미지의 개수
- channels : 이미지 채널 (흑백은 1개의 채널을 가지고, 컬러 이미지는 3개의 채널을 가진다.)
- width : 이미지의 높이와 너비를 나타낸다.

print구문 출력결과 ✍ 이미지 데이터 전처리하기
def imshow(img, title): plt.figure(figsize=(batch_size * 4, 4)) #출력할 개별 이미지의 크기 지정 plt.axis('off') plt.imshow(np.transpose(img, (1, 2, 0))) plt.title(title) plt.show()plt.figure(figsize=(batch_size * 4, 4))
- 출력할 개별 이미지의 크기를 지정
- batch_size : 이미지 배치 크기
- *4 : 출력할 이미지의 가로 길이
plt.axis('off')좌표축을 없앤다.
transpose(출력할 이미지, (배치사이즈, 가로 길이, 채널 수))
- np.transpose() 함수를 사용하여 이미지 데이터의 차원 순서를 변경하는 것
- 저대로 행렬 차원을 변경하여 imshow() 함수에 img를 전달한다.
- 저 순서대로 변경해야지 넘파이 형태로 matplotlib에서 출력이 가능하다.
plt.title(title)
- 이미지에 제목을 추가한다.
- title은 함수의 두 번째 인자로 전달된 제목
✍ 이미지 데이터 출력함수 정의하기
def show_batch_images(dataloader): images, labels = next(iter(dataloader)) #가져온 이미지의 크기는 (4, 28, 28, 1(배치 크기, 높이, 너비, 채널))이 됩니다. img = torchvision.utils.make_grid(images) #torchvision.utils.make_grid : 좌표에 이미지 픽셀을 대응시켜 그리드 형태로 출력한다. imshow(img, title=[str(x.item()) for x in labels]) #imshow 함수를 사용함으로써 데이터의 형태는 (채널, 높이, 너비)에서 (높이, 너비, 채널)로 변경된다. return images, labels✍ 이미지 출력하기
images, labels = show_batch_images(trainloader)
이미지 출력 결과 ✍ 배치 정규화가 적용되지 않은 모델 네트워크 만들기
class NormalNet(nn.Module): def __init__(self): super(NormalNet, self).__init__() self.classifier = nn.Sequential( nn.Linear(784, 48), #(28, 28) 크기의 이미지로 입력은 784(28×28) 크기가 된다. nn.ReLU(), nn.Linear(48, 24), nn.ReLU(), nn.Linear(24, 10) # FashionMNIST의 클래스는 총 열 개 ) #nn.Sequential을 사용하면 forward( ) 함수에서 계층(layer)별로 가독성 있게 코드 구현이 가능하도록 도와준다. def forward(self, x): x = x.view(x.size(0), -1) x = self.classifier(x) #nn.Sequential에서 정의한 계층 호출 return x # 배치 정규화가 적용되지 않은 모델 선언하기 model = NormalNet() print(model)** 과적합
- 훈련 데이터셋을 과하게 학습하는 것
- 일반적으로 훈련 데이터셋은 실제 데이터셋의 부분 집합이므로 훈련 데이터셋에 대해서는 오류가 감소하지만, 테스트 데이터셋에 대해서는 오류가 증가하는데 이 증가가 급격해지는 상태를 과적합이라고 부른다.

✍ 배치 정규화가 적용된 모델 네트워크 만들기
class BNNet(nn.Module): def __init__(self): super(BNNet, self).__init__() self.classifier = nn.Sequential( nn.Linear(784, 48), nn.BatchNorm1d(48), # 배치정규화가 적용되는 부분으로 48은 이전 계층의 출력채널과 똑같이 작성해줘야 함 nn.ReLU(), nn.Linear(48, 24), nn.BatchNorm1d(24), nn.ReLU(), nn.Linear(24, 10) ) def forward(self, x): x = x.view(x.size(0), -1) x = self.classifier(x) return x #모델 선언 model_bn = BNNet() print(model_bn)✍ 모델 학습하기
loss_arr = [] loss_bn_arr = [] max_epochs = 2 for epoch in range(max_epochs): for i, data in enumerate(trainloader, 0): inputs, labels = data opt.zero_grad() #배치 정규화가 적용되지 않은 모델의 학습 outputs = model(inputs) loss = loss_fn(outputs, labels) loss.backward() opt.step() opt_bn.zero_grad() #배치 정규화가 적용된 모델의 학습 outputs_bn = model_bn(inputs) loss_bn = loss_fn(outputs_bn, labels) loss_bn.backward() opt_bn.step() loss_arr.append(loss.item()) loss_bn_arr.append(loss_bn.item()) plt.plot(loss_arr, 'yellow', label='Normal') plt.plot(loss_bn_arr, 'blue', label='BatchNorm') plt.legend() plt.show()배치 정규화 위치

✍ 데이터셋 메모리로 불러오기
- 앞에서 불러오기는 했지만 이번에는 크기를 다르게 해서 불러오자
batch_size = 512 trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True)✍ 모델에서 사용할 옵티마이저와 손실함수 지정하기
loss_fn = nn.CrossEntropyLoss() opt = optim.SGD(model.parameters(), lr=0.01) opt_bn = optim.SGD(model_bn.parameters(), lr=0.01)💚 FASHIONMNIST 데이터셋을 통하여 드롭아웃 구현하기
✍ 데이터셋 분포 출력을 위한 전처리
N = 50 noise = 0.3 x_train = torch.unsqueeze(torch.linspace(-1, 1, N), 1) y_train = x_train + noise * torch.normal(torch.zeros(N, 1), torch.ones(N, 1)) x_test = torch.unsqueeze(torch.linspace(-1, 1, N), 1) y_test = x_test + noise * torch.normal(torch.zeros(N, 1), torch.ones(N, 1))
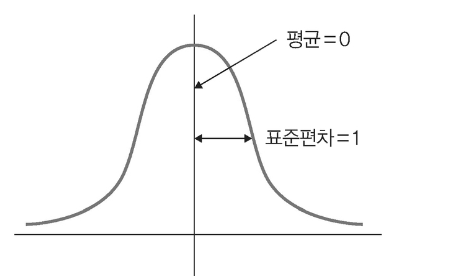
표준화
기존 데이터를 평균은 0, 표준편차는 1인 형태의 데이터로 만드는 것
- standard scaling(= z-score normalization)
StandardScaling() 수식

'딥러닝 > 이것저것' 카테고리의 다른 글
딥러닝(5) - 합성곱 신경망 구현하기 : 구현에 필요한 것들 모음 (0) 2023.03.18 딥러닝 모델 유형(4) - 인공신경망의 유형 (0) 2023.03.15 파이토치 자연어처리(16) - 최적화하기 (0) 2023.03.07 파이토치 자연어처리(2) - 파이토치 기초 (0) 2023.02.10 파이썬 스터디(1) - 문자열 (0) 2022.11.19