-
딥러닝 - 모델 유형(1) - 지도학습딥러닝/데이터분석 2023. 3. 11. 18:30
지도학습이란?
정답(레이블)을 컴퓨터에 미리 알려주고 데이터를 학습시키는 것
지도학습의 종류 : 분류(주어진 데이터를 정해진 범주에 따라 분류)와 회귀(데이터의 특성(feature)을 기준으로 연속도니 값을 그래프로 표현하여 패턴이나 트렌드 예측)


분류 모델 종류
1. K -nearest neighbor

새로운 입력(학습에 사용되지 않은 새로운 데이터셋)을 받았을 때 기존 클러스터
에서 모든 데이터와 인스턴스 기반 거리를 측정한 후 가장 많은 속성을 가진 클러스터에 할당하는 분류 알고리즘
= 과거 데이터를 사용해서 분류모형 만드는게 아님
=과거 데이터를 저장해 두고 필요할 때마다 비교 수행
= K 값 선택에 따라 새로운 데이터에 대한 분류 결과가 달라질 수 있다.

ex
예를 들어 새로운 입력 데이터 (빨간색 원 세개) 가 있을 때 새로운 입력에 대한 분류 진행
주어진 데이터 개수가 3개이므로 K=3이 된다.

새로운 입력 1 : 주변 범주 세개가 주황색이므로 주황색으로 원을 분류함
새로운 입력 2 : 주변 범주 두개가 주황색, 한 개가 녹색이므로 주황색으로 분류함
새로운 입력 3 : 주변 범주 두개가 녹색, 한개가 주황색이므로 녹색으로 분류함
K값 예측 과정

#라이브러리와 데이터 호출 import numpy as np #------ 벡터 및 행렬의 연산 처리를 위한 라이브러리 import matplotlib.pyplot as plt #------ 데이터를 차트나 플롯(plot)으로 그려 주는 라이브러리 import pandas as pd #------ 데이터 분석 및 조작을 위한 라이브러리 from sklearn import metrics #------ 모델 성능 평가 names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class'] #------ 데이터셋에 열(column) 이름 할당 dataset = pd.read_csv('../iris.data', names=names) #------ 데이터를 판다스 데이터프레임(dataframe)에 저장, 경로는 수정해서 진행 #데이터를 전처리하여 훈련 데이터와 테스트 데이터로 나누기 X = dataset.iloc[:, :-1].values #------ 모든 행을 사용하지만 열(칼럼)은 뒤에서 하나를 뺀 값을 가져와서 X에 저장 y = dataset.iloc[:, 4].values #------ 모든 행을 사용하지만 열은 앞에서 다섯 번째 값만 가져와서 y에 저장 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)# ------ X, y를 사용하여 훈련과 테스트 데이터셋으로 분리하며, 테스트 데이터셋의 비율은 20%만 사용 from sklearn.preprocessing import StandardScaler s = StandardScaler() #------ 특성 스케일링(scaling), 평균이 0, 표준편차가 1이 되도록 변환 X_train = s.transform(X_train) #------ 훈련 데이터를 스케일링 처리 X_test = s.transform(X_test) #------ 테스트 데이터를 스케일링 처리 #모델 생성하고 훈련하기 from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=50) #------ K=50인 K-최근접 이웃 모델 생성 knn.fit(X_train, y_train) #------ 모델 훈련(model이름.fit(훈련데이터들)) #모델 정확도 측청하기 : accuracy_score 라이브러리 불러오기 from sklearn.metrics import accuracy_score y_pred = knn.predict(X_test) print("정확도: {}".format(accuracy_score(y_test, y_pred)))
라고 출력된다.
K=50을 대입하였을 때 예측 값이 약 93%로, 수치가 높다. 그럼 최적의 K값을 구하고 그것에 대한 정확도를 파악해야함
-> for문을 사용해서 K값을 자동으로 1~10까지 할당하여 최적의 K값과 정확도를 찾자.
k = 10 acc_array = np.zeros(k) for k in np.arange(1, k+1, 1): #------ K는 1에서 10까지 값을 취함 classifier = KNeighborsClassifier(n_neighbors=k).fit(X_train, y_train) #------ for 문을 반복하면서 K 값 변경 #하고 아까처럼 분류기를 각 k값에 맞게 생성하기 y_pred = classifier.predict(X_test) #모델 학습하기(위의 내용과 똑같음) acc = metrics.accuracy_score(y_test, y_pred) #정확도 측정 acc_array[k-1] = acc max_acc = np.amax(acc_array) acc_list = list(acc_array) k = acc_list.index(max_acc) print("정확도", max_acc, "으로 최적의 k는", k+1, "입니다.")
K 값이 1일 때는 정확도가 100%이므로 k=1이 최적의 조건이다.
2. 서포트 벡터 머신
분류를 위한 기준선을 정의하는 모델
분류되지 않은 새로운 데이터가 나타나면 결정 경계(기준선)를 기준으로 경계의 어느 쪽에 속하는지 분류하는 모델입니다. 따라서 서포트 벡터 머신에서는 결정 경계를 이해해야 함

서포트 벡터 머신의 경계 결정

서포트 벡터 머신의 분류 과정

#라이브러리 호출 from sklearn import svm from sklearn import metrics from sklearn import datasets #사이킷런에서 제공하는 예시 데이터 라이브러리 from sklearn import model_selection import tensorflow as tf #텐서 플로우 불러옴 import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' #environ : 환경번수값 설정함 # TF_CPP_MIN_LOG_LEVEL : 로깅을 제어(기본값은 0으로 모든 로그가 표시되며, INFO 로그를 필터링하려면 1, WARNING 로그를 필터링하려면 2, ERROR 로그를 추가로 필터링하려면 3으로 설정) #데이터 전처리 하기 iris = datasets.load_iris() #------ 사이킷런에서 제공하는 iris 데이터 호출 X_train, X_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target, test_size=0.6, random_state=42) #------ 사이킷런의 model_selection 패키지에서 제공하는 train_test_split 메서드를 활용하여 훈련과 테스트 데이터셋으로 분리 svm = svm.SVC(kernel='linear', C=1.0, gamma=0.5) #------SVM : 선형 분류와 비선형 분류를 지원 (모델의 훈련방식 설정하기) + 라이브러리 불러와서 변수에 저장 svm.fit(X_train, y_train) #------ 훈련 데이터를 넣고 SVM 분류기를 훈련(훈련 모델 만들기) predictions = svm.predict(x_test) #------ 훈련된 모델을 사용하여 테스트 데이터에서 예측(모델이름.predict(test_data)) score = metrics.accuracy_score(y_test, predictions) print('정확도: {0:f}'.format(score)) #------ 테스트 데이터 (예측) 정확도 측정
SVM 분류 모델 : 선형 커널과 비선형 커널

# 결정 트리
데이터를 분류하거나 결괏값을 예측하는 분석 방법

결정 트리 예시
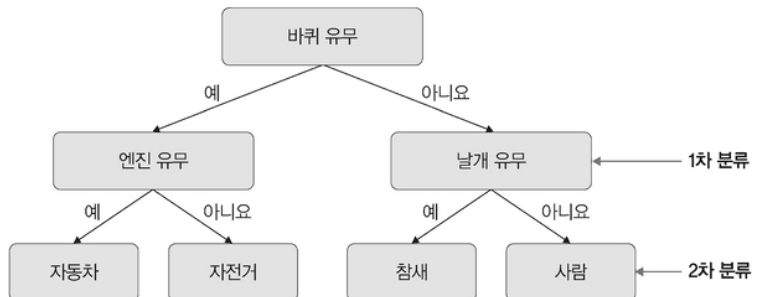
정보 획득 : 결정 트리로 분류할 떄마다 각 영역의 순도가 증가하고, 불확실성은 감소하는 것
** 순도와 불순도
순도 : 범주 안에서 같은 종류의 데이터만 모여 있는 상태
불순도 : 서로 다른 데이터가 섞여 있는 상태

정보획득(결정트리 불확실성 계산) 방법
1. 엔트로피
확률 변수의 불확실성을 나타낸 것

엔트로피 계산식

2.지니 계수
1. 로그를 사용할 필요가 없음 -> 엔트로피보다 손쉽고 간편하다.
지니 계산식
결정트리 과정
** 우리의 데이터는 죽었나 살았나(이 두 가지의 상태를 보는 것!)

#라이브러리 호출 import pandas as pd # 데이터셋 불러오기 df = pd.read_csv('./train.csv', index_col='PassengerId') #-----판다스로 tran.csv 파일을 로드해오기 print(df.head()) print(df.tail()) print(df.DESC())

#데이터 전처리 해주기 #전체 데이터 칼럼 중 분석에 필요한 칼럼을 추출하는 과정 #전체 데이터 칼럼 추출 df = df[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Survived']] #------ 승객의 생존 여부를 예측하려고 ‘Pclass’, ‘Sex’, ‘Age’, ‘SibSp’, ‘Parch’, ‘Fare’ 사용 #cabin 데이터 칼럼은 생존과 아무 상관이 없기 떄문에 그냥 뺴버렸음 #df = df [[원하는 칼럼]]은 원하는 칼럼에 해당되는 데이터셋만 남겨놓고 나머지는 자동 삭제시키는 것 #원하는 칼럼 선택해서 데이터셋의 값을 바꾸기 df['Sex'] = df['Sex'].map({'male':0, 'female':1}) #------ 성별을 나타내는 ‘sex’ 를 0 또는 1의 정수 값으로 변환(둘 중하나만 해당되는 sex는 범주형 데이터 이므로 mmap을 사용해서 반환해준다. #결측치 처리하기 df = df.dropna() # 여기서는 값이 없는 데이터를 삭제 시켜줘버림 #x와 y르 나누기 x = df.drop('Survived', axis=1) #Survied를 제외한 칼럼들인 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare'에 해당되는 데이터들은 x임 y = df['Survived'] #------'Survived'를 예측 레이블로 사용한다. #x를 훈련과 테스트 데이터셋으로 나누고 y도 훈련과 테스트 데이터셋으로 나누기 #훈련 테스트 분류할 수 있는 모델 불러오기 : sklearn.nodel_selection from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1) #임의로 train, test 분류하는 것을 train_test_split 라이브러리임 #결정 트리 라이브러리로 모델 생성 from sklearn import tree model = tree.DecisionTreeClassifier() #훈련 데이터셋으로 모델 훈련시키기 model.fit(x_train, y_train) #테스트 데이터셋으로 모델에 대한 예측 진행 y_predict = model.predict(X_test) from sklearn.metrics import accuracy_score accuracy_score(y_test, y_predict) #------ 테스트 데이터에 대한 예측 결과를 보여 줍니다. #혼동행렬로 성능 측정하기 from sklearn.metrics import confusion_matrix pd.DataFrame( confusion_matix(y_test, y_predict), columns = ['Predicted Not Survival', 'Predicted Survival'], index = ['True Not Survival', 'True Survival'] )
정확도 : 83%

** 혼동행렬
알고리즘 성능 평가에서 사용됨 (accuracy와 함께 정확도 평가)

True Positive: 모델(분류기)이 ‘1’이라고 예측했는데 실제 값도 ‘1’인 경우
True Negative: 모델(분류기)이 ‘0’이라고 예측했는데 실제 값도 ‘0’인 경우
False Positive: 모델(분류기)이 ‘1’이라고 예측했는데 실제 값은 ‘0’인 경우
False Negative: 모델(분류기)이 ‘0’이라고 예측했는데 실제 값은 ‘1’인 경우
**주어진 데이터를 사용하여 트리 형식으로 데이터를 이진 분류(0 혹은 1)해 나가는 방법이 결정 트리이며, 결정 트리를 좀 더 확대한 것(결정 트리를 여러 개 묶어 놓은 것)이 랜덤 포레스트(random forest)이다.
회귀
1. 로지스틱 회귀

'딥러닝 > 데이터분석' 카테고리의 다른 글
Tensorflow - softmax (0) 2023.05.14 Tensorflow - Linear Regression (0) 2023.05.09 딥러닝 모델 유형(2) - 비지도 학습 (0) 2023.03.12 파이토치 자연어처리(13) - 로지스틱 회귀 (0) 2023.03.04