-
파이토치 자연어처리(1) - 텍스트 인코딩 , 계산그래프딥러닝/자연어처리 2023. 2. 9. 17:26
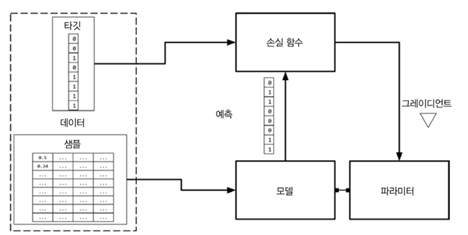
지도학습이란?
샘플(예측에 사용하는 아이템. 입력값 x)에 대응하는 타깃(예측값. 샘플에 상응하는 레이블 y)의 정답을 제공하는 것

모델 : 수학식이나 x를 받아 타깃 레이블(y)를 예측할 수 있도록 하는 것
파라미터 : 가중치(w or w^)
예측 : 모델이 추측하는 타깃값으로 추정값이라고 부른다. 주로 ^ 표시를 사용함 예를 들어서 타깃값(y)의 예측은 y^이라고 함
손실함수 (L):
1. 훈련데이터에 대한 예측값(y^)이 타깃과 얼마나 멀리 떨어져 있는지 비교하는 것
2. 타깂과 예측값이 주어지면 손실함수는 손실 계산함 -> 손실이 낮을 수록 예측을 잘함
L(y, y^)로 표현함
확률적 경사 하강법
데이터 포인트를 하나 또는 일부 랜덤하게 선택하여 그레디언트를 계산하는 것
순수 SGD : 데이터 포인트1개 사용 . 거의 잘 사용하지 않음
미니배치 SGD : 데이터 포인트 2개 이상 사용
샘플과 타깃의 인코딩
왜 사용?
샘플(텍스트)을 머신러닝 알고리즘에서 사용하기 위해서!
텍스트를 수치로 표현하는 것. 즉 수치 벡터로 변환해주는 것이라고 생각하면 됨!
인코딩 방식
1. 원-핫 표현
0백터에서 시작해 문장이나 문서에 등장하는 단어에 상응하는 원소를 1로 설정함

위의 문장을 토큰으로 나누고 구두점을 무시한 다음, 모두 소문자로 바꾸게 되면,
(time, fruit, files, like, a, an, arrow, banana)
가 되는데 여기서 수치벡터는 8이 되고, 가 단어들은 8차원 원-핫 벡터로 표현이 가능하다.
1w = 한 단어의 토큰의 원-핫 표현을 의미함

예들 을어서, 'like a banana'의 원-핫 표현은 3(1의 개수) x 8(총 차원의 개수)크기의 행렬이다. 왜냐하면,
(time, fruit, files, like, a, an, arrow, banana)
위에 대입을 해보면,
(0,0,0,1,1,0,0,1)
8개 중 3개가 1이 나오게 된다.
2. TF 표현
원-핫 표현을 통하여 출력한 각각의 원소의 개수를 표현함
// 원-핫 인코딩 방식을 이용한 TF 표현 출력 from sklearn.feature_extraction.text import CountVectorizer import seaborn as sns corpus = {'Time files like an arrow', 'Fruit files like a banana'} one_hot_vectorizer = CountVectorizer(binary=True) //binary =True는 CountVectorizer 클래스에서 원-핫 인코딩 형식으로 변환하는 것 //CountVectorizer는 최소 행렬을 반환하므로 toarray()메서드를 사용하여 밀집행렬로 위의 행렬을 바꿔 출력해줌 one_hot = one_hot_vectorizer.fit_transform(corpus).toarray() vocab = one_hot_vectorizer.get_feature_names() sns.heatmap(one_hot, annot = True, char=False, xticklables=vocab, yticklables= {'Sentence 1','Sentence 2'} )위의 코드 작동 결과

3. TF- IDF 표현
TF는 등장 횟수에 비례하여 단어에 가중치를 부여하는데, TF-IDE는 등장횟수와 반비례하여 단어에 가중치를 부여함.
즉, 벡터 표현에서 흔한 토큰의 점수를 낮추고 드문 토큰의 점수를 높임

IDF(w) : 토큰 하나에 대한 가중치
nw : 단어 w를 포함한 문서의 개수
N : 전체 문서 개수
TF - IDF 점수 = TF(w) * IDF(w)
TF-IDF 표현 만들기
from sklearn.feature_extraction.text import TfidVectorizer import seaborn as sns tfidf_vetorizer = TfidVectorizer() corpus = { 'Time files like an arrow', 'Fruit files like a banana } tfidf = tfidf_vectorizer.fit.transform(corpus).toarray() sns.heatmap(tfidf, annot = True, char = False, xticklabels = vocab, yticklables={'Sentence 1', 'Sentence 2'})
계산 그래프
위의 지도 학습 데이터 흐름 구조를 간단하게 위해서 사용함 . 수학식을 추상적으로 모델링
조금 말이 모호한데, 예시를 보자면
y = wx + b라는 식이 있다 해보자. 이 식은
z = wx
y= z+b로 나누어서 쓸 수 있음
여기서 노드를 곱셈, 덧셈, 뺄셈 같은 연산자로 하면,

이렇게 표현이 가능함.이런 것을 계산 그래프라고 하는데....이걸 더 어떻게 설명을 해야 될지 모르겠다.